Flows
Flows contain your automation logic in the form of flow scripts. With them, you define what you want to automate and how to do so. This makes them your most important resource in Engine.
The flow script is written in Python. Executions of flows will process the handler function of the flow script.
Depending on the complexity of your automated process, it can consists of one or many flows. Executions of flows can start executions of other flows and pass inputs and outputs between each other.
You don't need to know Python to use Engine. Engine provides many features that make it possible to run and monitor flows without coding experience. (e.g. Dependency Visualisation, Script Visualisation, Execution Live Monitor)
Creating or modifying flows, on the other hand, requires some knowledge of Python.
Small flows with well-defined scope can can be reused bydby many automated processes. We recommend breaking automated processes down into several flows which automate specific tasks. In addition to simpler re-use, it also makes it easier to maintain and extend your automated processes.
Working with Flows
You can create flows in the User Interface by pressing the "Create" button and selecting "Flow":


The buttons to create a flow
The new flow is opened and you can directly modify the script.
The flow script editor provided in the Engine user interface comes with built-in Linting and supports Breakpoints and Step Through. If you prefer, you can also use an offline editor of your choice.. You can synchronise your offline work with Engine using the Git Integration.
Engine does not store older versions of your flows when making changes. Make sure to have a backup of your flows if you make significant changes. Or even better: use the Git Integration.
Clicking the "Run" button in the flow view will create an execution of the flow and automatically redirect you to the execution view. Read more about executing flows in the documentation on Development and Productive Mode.
Interaction between Flows
Parent-child relationships
- Executions of flows can create executions of other flows.
- When an execution creates another execution, a parent-child relation is established between them.
- Each execution is represented in a tree structure, where it can have only one parent and may have multiple children.
- Executions without a parent form the trunk of the tree and appear as top-level executions in the Execution Live Monitor.
Parent-child relationships are independent of dependencies. However, dependencies can mostly align with parent-child relationships.
Executions of flows can create executions of other flows.
Create a child execution.
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
my_flow = this.flow('my_other_flow_name')
return this.success('all done')
When an execution creates another execution, a parent-child relation is established between them:
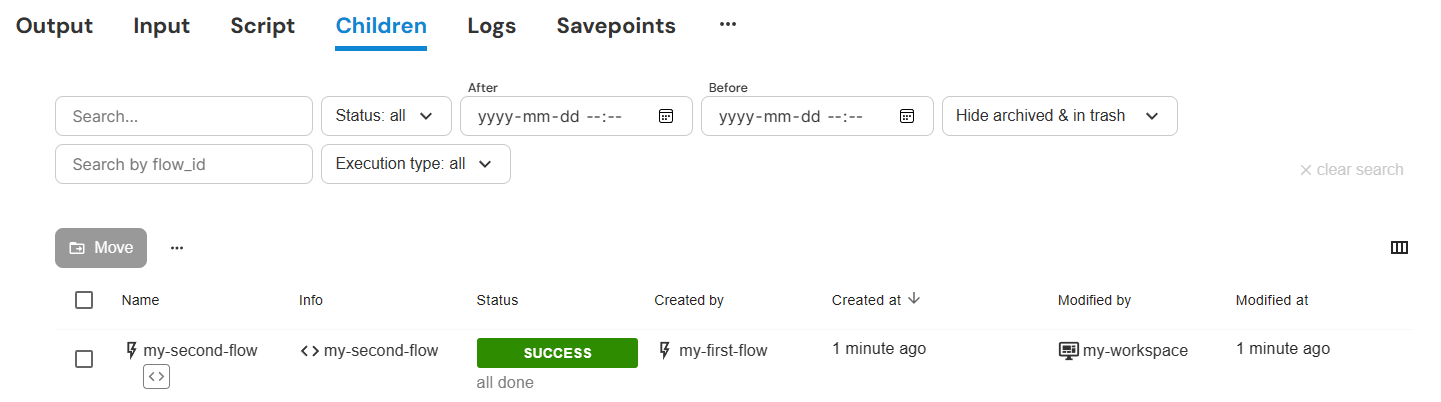
The parent execution lists all children in the "Children" tab

The child execution has a button to navigate to the parent
These relationships are primarily used to track logical and hierarchical connections between executions, aiding in monitoring, debugging, and traceability across flows.
Dependencies
- Executions of flows can be dependent on other executions.
- When an execution waits for another execution a dependency relation is established between them.
- Dependencies are represented as a directed graph, where each execution can depend on multiple others and, in turn, can be a dependency for multiple executions.
- Dependencies are shown in the dependency visualization in each execution (see more here).
The dependency visualization is designed to simplify understanding execution order and coordination.
While it can include parent-child relationships, it is not a full representation of parent-child hierarchies.
It currently only shows the dependencies of the currently opened execution and (if it exists) one level up of dependee executions (see more here).
Take a look at the below flow scripts to learn more about how to create a dependency relation between executions in different ways.
A dependency relation between executions can be created implicitly:
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
child_execution = this.flow(
'another-flow',
run=True # Main execution has to wait for this child execution
)
return this.success('All done.')
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
child_execution = this.flow(
'another-flow',
run=False # Main execution does not wait for the child execution (not a dependency)
)
child_execution.run(wait=True) # Wait for the child execution later on, creates the dependency
return this.success('All done.')
A dependency relation between executions can be created explicitly:
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
child_execution = this.flow(
'another-flow',
run=False # Main execution does not wait for the child execution (not a dependency)
)
this.dependency(child_execution) # Dependency is later defined explicitly
return this.success('All done.')
To add dependencies to executions started by other executions:
In this example the current execution waits for the other executions in the loop one by one. It starts with the first execution found if that one fails, the current execution will also fail immediately. If the first execution succeeds, it moves on to wait for the next one, and so on until all are processed.
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
# find an execution
for execution in system.executions(filter_=...):
this.dependency(execution) # execution could be created by some other flow
return this.success('All done.')
It is also possible to wait for all executions at once:
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
this.dependency(*system.executions(filter_=...))
return this.success('All done.')
The table below provides a summary of key conceptual differences between parent-child relationships and dependencies.
| Aspect | Parent-Child | Dependency |
|---|---|---|
| Establishment | Established when an execution (parent) creates a new execution (child) | Established when an execution waits for one or more other executions |
| Purpose | Tracks creation/origin of executions | Defines execution order and coordination |
| Structure | Tree (1 parent, many children) | Directed graph (many-to-many) |
| Directionality | One-way (creator → created) | One-way (dependent → dependee) |
| Multiplicity | One parent, multiple children | Multiple dependencies and dependees |
Validating flow existence
Referencing a flow does not validate its existence. Even if a flow with the provided name or ID does not exist, the Flow API will not throw an error.
For example:
this.log(system.flow('some-name'))
This will log <flow some-name>, even if the flow 'some-name' does not exist or if 'some-name' does not refer to an actual flow.
Therefore, it is necessary to explicitly validate the existence of a flow before performing updates or modifications through the Flow API.
How to access and validate if the flow actually exists
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
flow = system.flow('example_flow_name')
if flow.exists():
this.log("flow exists!")
return this.success('all done')
else:
return this.error("flow does not exist!")
Passing values
Interactions between flows can be leveraged to build large and complex processes from small and maintainable elements.
Let’s look at how you can break a process into parts. Note that we pass values between flows multiple times, and one flow’s result influences what the other flow does.
Flow 1 - Main Process
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
initial_value = 42
new_value = this.flow(
'Calculator',
name='calculate new value',
initial_value=initial_value, # passing initial_value to the flow 'Calculator'
).get('output_value')['result'] # getting 'result' field of the output_value of the flow 'Calculator'
this.flow(
'Messenger',
name='create message with result',
message_value=new_value, # passing new_value to the flow 'Messenger'
)
return this.success('all done')
Flow 2 - Calculator
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
# getting initial_value from the 'initial_value' field of the input_value
initial_value = inputs['initial_value']
# doing some (not very) complex calculations
result = initial_value * 1
# saving result into the 'result' field of the output_value
this.set_output(result=result)
return this.success('all done')
Flow 3 - Messenger
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
# getting message_value from the 'message_value' field of the input_value
message_value = inputs['message_value']
# creating message
this.message(
subject='Message',
message=f' The value is: {message_value}',
)
return this.success('all done')
In the previous example we passed numbers as values. It is also possible to pass Cloudomation Resources.
Flow 1 - Main Process
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
# get a Cloudomation resource
setting = system.setting('my-setting')
# pass the Cloudomation resource to the flow
this.flow(
'Setting Writer',
name='write setting',
setting=setting,
)
return this.success('all done')
Flow 2 - Setting Writer
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
# get the passed Cloudomation resource
setting = inputs['setting']
# write the setting
setting.save(value='my value')
return this.success('all done')
These examples are, of course, very simple, and it might be easier to implement all functionality within a single flow. Breaking processes into smaller flows becomes increasingly relevant as complexity grows and when considering future scalability.
Handling Errors
If a child execution fails, it will raise an exception, causing the parent execution to fail as well. To avoid the parent failing, you can catch the exception:
Create a child execution and handle errors.
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
try:
my_flow = this.flow('my_other_flow_name')
except flow_api.DependencyFailedError:
this.log('my_other_flow_name failed')
else:
this.log('my_other_flow_name succeeded')
return this.success('all done')
Please refer to Exceptions for details about error handling.
Immediate execution control
The run parameter allows the user to control whether the child flow should instantly run or not.
- True: The flow runs immediately.
- False: The flow execution is created but not started.
In the example below, you can observe this behavior. The script runs the flow child_flow_name which creates a child execution of it. Since the run parameter is set to False the execution status will be initially "Paused" until a manual start.
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
# Create child execution but do not run it yet
child_execution = this.flow(
'another-flow',
run=False # Execution is not started immediately
)
# Start execution later
child_execution.run(wait=True)
this.log('Flow executed after manual start.')
return this.success('Manual execution started successfully.')
Synchronous execution
Synchronous execution ensures that the script waits for the child execution to complete before proceeding. In the example below, since the parent execution waits for the child execution to finish, it is possible to determine whether the child execution completed successfully.
To control whether the interaction between flows are synchronous or asynchronous use the wait parameter of the run() method.
This parameter is passed when starting a child execution (e.g., run(wait=False)) and it determines whether the parent execution will wait immediately for a child execution to complete after starting it.
If wait=True the parent will pause and wait for the specific child to finish executing before continuing with the next line of code in the parent.
This creates a dependency between them and causes the parent execution to behave synchronously with the child.
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
child_execution = this.flow(
'sync_flow',
wait=True # Ensures that the parent waits for the child execution to finish
)
if child_execution.get('status') != 'ENDED_SUCCESS':
return this.error('Child flow execution failed!')
this.log('Synchronous execution completed successfully!')
return this.success('Flow executed synchronously')
Asynchronous execution
Asynchronous execution enables the parent execution to continue without waiting for the child execution to complete. This can be done via the wait=False parameter.
If wait=False the parent will not wait for the child execution to complete immediately. It allows the child to run asynchronously, while the parent execution continues from the subsequent lines of code.
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
async_execution = this.flow(
'async_flow',
wait=False # Proceed without waiting for the child execution
)
this.log(f'Async flow triggered.')
return this.success('Flow executed asynchronously')
Wait for multiple executions to end
When triggering multiple asynchronous executions, you can wait for all of them to complete by using the return_when parameter with the wait_for() method on the execution.
Unlike the wait parameter, return_when gives you control after multiple asynchronous flows have been started.
This provides more flexibility in managing and customizing the waiting behavior for multiple concurrent executions.
return_when only matters if you have already started child flows asynchronously wait=False and want to control further execution based on their status.
wait=False starts both child flows asynchronously without waiting for them to finish.
this.wait_for(..., return_when='ALL_ENDED') controls when the parent resumes execution:
In this case, the parent waits until both flows finish.
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
async_child_1 = this.flow('flow_1', wait=False)
async_child_2 = this.flow('sync_flow', wait=False)
this.wait_for(
async_child_1,
async_child_2,
return_when='ALL_ENDED' # Options: ALL_ENDED, ALL_SUCCEEDED, FIRST_ENDED
)
this.log('All children executions have completed.')
return this.success('Synchronized all async flows successfully')
Interaction with other services: connectors
In order to connect with services outside of the Engine platform, you can create ad-hoc connections directly from a flow script using the this.connect() method, as shown in the example below.
This allows you to define and trigger a connection to an external system on the fly without relying on a preconfigured connector.
Creating a connection execution from your flow is simple:
import flow_api
def handler(system: flow_api.System, this: flow_api.Execution, inputs: dict):
my_connection = this.connect(
connector_type='GIT',
command='get',
repository_url='https://example.com/path/to/repo.git',
)
# read the outputs of the connection and log them
this.log(my_connection.get('output_value'))
return this.success('all done')
Alternatively, you can use an existing connector to create a connection. When you create a connection using a connector, the base configuration stored in the connector is applied automatically.
However, it's also possible to override any of the connector's stored configuration by providing parameters directly in the flow script. These inline parameters will take precedence over the corresponding values defined in the connector for that specific execution, providing flexibility to adjust behavior dynamically without modifying the connector itself.
To explore the different types of connectors available, see the Connector Types.
Specifying location inheritance
The location_inheritance option determines how location associations are handled when a flow is executed.
Location inheritance options
- created_by: The flow execution inherits the same location as the creating identity.
- default: Defaults to the workspace-level "Default Project" or "Workspace" for records that cannot belong to a project.
- wrapped_resource: This location is tied to the innermost wrapped resource (specific to executions based on a resource, not ad-hoc).
- resource: The location is associated with the resource on which the execution is based (if applicable).
When location_inheritance is unset for an execution, the default behavior depends on the identity that triggered the execution. If the execution is triggered by any identity type other than an execution, the default inheritance is wrapped_resource. If the triggering identity is an execution, the default inheritance is created_by.
Use cases for inheritance options
It might be helpful to review the example scenarios below to understand when to use which location inheritance type
created_by
Use this type when a workflow is initiated by a manual trigger (user identity), and the flows must run within the same project or bundle associated with the user’s workspace settings.
child_execution = this.flow(
'archive-log-flow'
).run(
location_inheritance='created-by'
)
default
Use this type when you want to ensure the execution gets processed within the workspace-wide default location, regardless of the triggering identity.
child_execution = this.flow(
'archive-log-flow'
).run(
location_inheritance='default'
)
wrapped_resource
Use this type when the execution is based on a deeply wrapped resource and you need the location inheritance to maintain consistency with that specific resource.
child_execution = this.flow(
'api-data-processing-flow'
).run(
location_inheritance='wrapped_resource'
)
resource
Use this type when the execution is based on a resource and must inherit the location of the specific resource (e.g., a custom object) rather than another context.
child_execution = this.flow(
'equipment-operations-flow'
).run(
location_inheritance='resource'
)